Помимо основной работы, я занимаюсь своим небольшим побочным проектом, в основном на выходных. И есть особенность что отличает такие проекты – ты можешь уделять задачам столько времени, сколько посчитаешь нужным. На работе это не так.
В рабочее время у тебя есть дедлайн, нужно предоставить фичу реализованной в какой-то срок. И это даже хорошо, это организует. Но это плохо, если фича которую реализуешь задаёт архитектуру для проекта, и в последствии будет неоднократно изменяться и расширяться. Архитектуру лучше сразу делать хорошей, ибо рефакторинг будет очень болезненный.
Одна из составных частей моего проекта – чтение и распознавание текста с внешних ресурсов (сайтов, проще говоря).
Переписав три раза код, наконец получил то что мне нравится. В этом посте вкратце расскажу как я это вижу.
Задача
Итак, мои требования таковы:
-
Чтение с внешних ресурсов. Оно может происходить по-разному, в разных форматах и протоколах. Может оказаться так, что данные будут предоставляться после авторизации, через протокол
httpsили вообще в виде локально доступного файла. (Это может быть .xls к примеру) Надо предусмотреть возможность добавления новых источников. -
Сайты с которых происходит считывание могут иметь самую разную структуру. Иногда информация о конкретном предмете (товар, в моём случае) может быть размазана по нескольким страницам.
-
Удобное масштабирование. Число источников может вырасти очень стремительно. Нужно уметь раскидывать задачи и данные на несколько серверов.
-
Обработка ошибок. Ресурс источник может внезапно поменять структуру DOM, нужно адекватно на это реагировать. Кроме того, мне не хотелось бы, чтобы весь процесс синхронизации валился из-за одной страницы, на которой формат оказался немного другим от ожидаемого.
-
Возможность производить обработку на разных платформах. К примеру, я так и не нашёл подходящего гема для работы с русской морфологией, а вот для python есть подходящий пакет. Хочу иметь возможность загрузить страницу на Ruby, а разбить и распознать – на Python.
-
Версионирование загруженных данных. На тот случай, что если в распознающем коде закралась ошибка – быстро и безболезненно откатить на старую версию.
Идея
Для того чтобы удовлетворить 2-й и 3-й пункт необходимо загрузку разбить на отдельные независимые части. Напрашивается создание нескольких воркеров, каждый для какого-то конкретного куска, например:
- Воркер1: Получение списка категорий, добавление их в очередь.
- Воркер2: Получение списка страниц, добавление их в очередь.
- Воркер3: Получение списка товаров с конкретной страницы, добавление их в очередь.
- Воркер4: Чтение информации о конкретном товаре.
Нужен менеджер очередей, вроде DelayedJob (ныне порицаем), Sidekiq. Я выбрал RabbitMQ для работы с очередями. Понравился своими бенчмарками, гибкостью и Erlang’ом.
Итак, воркер получает аргументы для выполнения из сообщения (из очереди RabbitMQ), выполняет обработку, и забрасывает обратно в другие очереди другие куски для обработки.
Для простоты в каждой задаче для воркера обрабатывается одна страница.
Получаем что-то вроде рекурсивной функции, выполнение которой можно в любой момент остановить, починить, и снова продолжить. Ляпота =)
Кроме того, достигается пункт 5. ВоркерN может быть написан на другой платформе, главное иметь клиент AMQP, для подкючения к message broker.
Версионирование и хранение результатов
Итак, мы каким-то образом получаем сырые (raw) данные с сайта, потом их
распознаём, и как-то сохраняем как распознанные индексируемые поля (fields).
Однако, если данные не изменились, то распознавание (превращение raw в fields)
будет происходить всё равно. Это плохо. Кроме того, само распознавание может
быть довольно тяжёлой операцией – кто знает, может мне придётся прикрутить
нейронную сеть распознающую картинку или ещё что.
Можно сохранять сырые данные, при синхронизации сравнивать их, а по-необходимости
производить распознавание (raw в fields). Но тогда возникает следующая проблема:
нам захочется посмотреть в какой расцветке (варианты окраски) продавался товар
три месяца назад. Мы загружаем старую версию сырых данных, распознаём, и…
получаем неправильные данные. Потому что за три месяца назад сырые данные
выглядели не так как сейчас, и сегодняшний код не может их корректно распознать.
Поэтому необходимо хранить и сырые данные, и уже вычисленные поля. Для каждой версии.
Распознавание
Вообще, распознавание напрямую не связано с загрузкой. Кроме того, оно может быть тяжёлой операцией, следует выделить его в отдельный воркер, с отдельной очередью.
Кроме того, как я говорил выше, на каждую версию приходится одна страница, соответственно на один товар может приходиться несколько версий. Поэтому версии снабжаются идентификатором товара, к которому относятся.
Сборка из версий
После того как мы всё загрузили и всё распознали, мы имеем несколько распознанных записей для каждого товара. Одна запись – одна страница.
Необходимо их объединить в одну запись, которую уже можно отдавать как актуальную.
Решение
Итак, я разбил код весь на следующие части:
Version– модель в которой хранятсяrawиfields.Scraper– воркер занимающийся загрузкой и выдёргиванием сырых данных с сайтаScanner– воркер занимающийся распознаванием версийAssembler– воркер группирующий версии по идентификаторам, объединяющий их в готовую запись о товаре, которой можно пользоваться.
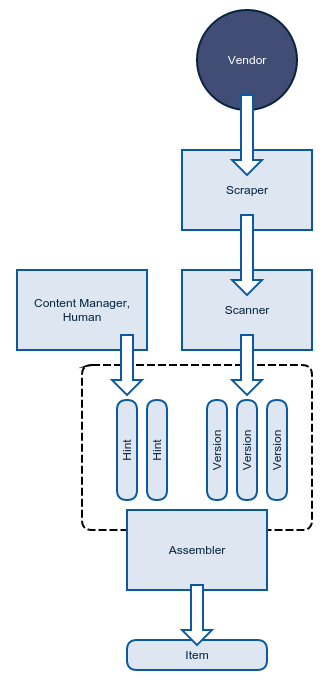
Каждый поставщик (источник) имеет свой набор scrapers и scanners, конкретно для его сайта. Однако код assembler для всех общий.
Поэтому fields должны соответствовать определённому формату, тогда как raw
у каждого поставщика может иметь свою структуру.
Кроме того осознал ещё одну проблему: если какой-то товар неправильно распознаётся, и это единичный случай, то лучше дать возможность сделать менеджеру хотфикс, чем ждать пока программист исправить scanner и заново запустит распознавание.
Так органичным образом добавилась ещё одна сущность:
Hint– модель описывающая отображение (rawвfields) и имеющая приоритет над распознанным при сборке.
Хочу отметить, что набор значений raw и fields жёстко не связан. Scanner
может получить на вход десять различных raw полей, и выдать только один field.
Либо наоборот, из одного raw['title'] вычислить марку товара, материал изготовления,
и уровень грамотности контент-менеджера, и бог знает ещё что.
И для того чтобы понимать, какие fields нужно вычислить, при изменении лишь
одного поля, нужно задать зависимости между raw и fields. Итак, в наши модели
Version и Hint добавляется ещё один столбец deps от слова dependencies.
Scraper
Люблю декларативный стиль.
Я искал для себя подходящий инструмент для вычленения сырых данных из DOM. Нашёл неплохой гем PageObject позволяющий декларативно объявлять элементы на странице и работать с ними.
Вообще гем предназначен в первую очередь для e2e тестирования, но это ничего. Проблема в том, что он работает только с браузерами. Для меня, в большинстве случаев, браузер это overkill, можно данные получать и простым парсингом тела ответа.
Может плохо искал, но так и не нашёл способа заставить PageObject работать без браузера (разумеется с отключением фич).
Поэтому пришлось запилить небольшой DSL. Вот пример использования:
class FooBarVendor::ItemScraper < Scraper # подключаем самописный DSL для работы с HTML include Makhno # присутствие строго одного элемента one :title, css: '.product-details .product-content > h1', # перед manipulate, элемент будет преобразован в значение value: ->(e) { e.text.strip } one :description, css: '.product-details .product-content .descr', value: ->(e) { e.text.strip } one :price, css: '.product-details .product-content .price strong', value: ->(e) { e.text.strip } # один либо более элементов many :images_urls, optional: true, # послабление: ноль либо более элементов css: '.product-details .product-images > a', value: ->(e) { normalize_url(e.attr('href'), @vendor.domain) } many :no_image_marker, optional: true, css: '.product-details .product-images > img', value: ->(e) { true } many :breadcrumbs, css: '.main-content .breadcrumbs li', value: ->(e) { e.text.strip } # можно добавить ещё объявлений, описывающих структуру DOM. # просто чтобы быть уверенным что поставщик ничего не менял. # Этот метод выполняется только если все элементы найдены и их value вычислен # если каких-то элементов нет, то воркер падает с ошибкой. def manipulate if images_urls.empty? raise "Images not found, nor placeholder either" unless no_image_marker build_event(@message, message: 'no-images-for-item', info: true).save! end @version.raw = { title: title, description: description, price: price, category_title: breadcrumbs[-2], images_urls: images_urls } end end
В классе Scraper описаны методы вроде normalize_url и build_event,
объявляются переменные-члены vendor, message и подобные.
А вообще он наследуется от Worker.
Хочу ещё добавить более умные валидации, вроде:
require_exclusively :images_urls, :no_image_marker
Чтобы не делать проверки вроде if images_urls.empty?, что можно увидеть выше.
А как же другие источники? Достаточно реализовать отдельный модуль, который будет предоставлять поля для manipulate, предоставлять какие-то инструменты для задания описаний и всё.
Scanner
Нам необходимо описать способ вычисления для каждого поля, а также задать зависимости. Я это сделал так:
class FooBarVendor::ItemScanner < Scanner field :title, using_raw: [:title] do |title| title end field :volume, using_raw: [:title] do |title| volume_from_title(title) end field :brand, using_raw: [:category_title] do |category_title| brand_from_title(category_title) end field :images, using_raw: [:images_urls] do |urls| urls.map do |url| uploader = ItemImageUploader.new(@version, url) uploader.retrieve_from_store!(uploader.filename) unless uploader.file.exists? uploader.store!(open("#{@vendor.protocol}://#{url}")) end { original: uploader.filename } end end private def volume_from_title(title) if fetched = title.scan(/(\d+)\s?(мл|ml)/i).first { value: fetched.first.to_i, unit: 'ml' } end end def brand_from_title(title) # skipped end end
Scanner также как и Scraper наследуется от Worker.
Оба этих DSL-ля активно работают с Version, но всё это спрятано в базовых классах. Описывается только самый минимум, необходимый для функционирования.
Клёвые DSL-и, делись!
Пока не готов. Если делиться, то это нужно оформлять как положено – в гем. У меня пока нет времени. Кроме того, сейчас они переплетены с моей логикой. Их можно будет выделить и использовать независимо, но я пока не готов этим заняться.
Кроме того, я только начал реализовывать проект. Выпущу в продакшен, получу опыт, доведу их до необходимого состояния, учту пропущенные сейчас крайние случаи.
Assembler
Последняя часть – сборщик. Собирает конкретную запись товара, с полями которые можно индексировать. Но об этом – в следующем посте.
To be continued.